Le deep learning est un champ du machine learning qui a fait énormément parler de lui ces dernières années notamment du fait de toute les promesses qui y sont liées.
De nombreuses personnes y ont même prédit la fin de l'intelligence humaine voire même de l'humanité.
Bon OK, la j'exagère un peu. Et je vous troll.
Néanmoins, les ingénieurs à l'origine des algorithmes de deep learning sont directement allés chercher leurs inspirations dans la configuration des neurones du cerveau humain pour concevoir ces derniers.
Et force est de constater que ça a plutôt bien réussi et qu'un grand bond dans l'intelligence artificielle a été constaté.
Dans cet article, je vous exposerais :
Ce qu'est exactement le Deep Learning
Qu'apporte réellement de nouveau le Deep Learning comparativement au machine learning
Qu'elle ce qui à donné naissance au Deep Learning?
Le deep learning est un sous-domaine du machine learning qui lui même est un sous-domaine de l'intelligence artificielle.
En effet, « Machine learning » signifie en français apprentissage machine. C’est donc un domaine qui est composé d’un ensemble de techniques qui permettront aux machines d’apprendre par elle-même à résoudre un problème.
Parmi cet ensemble de techniques, il y a un sous-ensemble de techniques d’apprentissage qu’on appelle communément le «deep learning » qui signifie en français apprentissage profond.
Ce sous-ensemble de techniques d'apprentissage regroupe toutes les techniques de machines learning utilisant des réseaux neuronaux profonds (Deep: en anglais) pour apprendre à réaliser des tâches et à résoudre des problèmes.
Ce terme comme on le verra par la suite est lié aux réseaux de neurones qui l'on a remarqué plus ils sont profond et plus ils sont puissants.
Le deep learning est un champ du machine learning qui a fait énormément parler de lui ces dernières années notamment du fait de toute les promesses qui y sont liées.
En effet celui-ci nous est vendu à toutes les sauces, par Google et compagnie. À tel point que dernièrement un ami me disait qu'il se passionnait depuis des années pour cela.
La vérité est que le Deep Learning n'a rien apporté de nouveau en soi dans le sens ou l'on savait déjà faire toutes les taches qui sont effectuées grâce au deep learning auparavant en utilisant les algorithmes classiques de machines Learning.
Ceci étant, la seule chose que la venue du Deep Learning a faite c'est de permettre au chercheur d'obtenir de bien meilleures performances sur les jeux de données communément utilisés par la communauté qu'avec le machine learning.
Et preuve en est que :
Avant l'arrivée du Deep Learning, pour effectuer de la reconnaissance d'image, les chercheurs extrayaient à l'aide de formule mathématique les propriétés des objets présents dans l'image et les envoyaient à un algorithme de classification.
Après l'arrivée du deep learning. l'image est directement passée en entrée d'un réseau de neurones et la reconnaissance est effectuée automatiquement sous couvert que l'on dispose préalablement de suffisamment de données pour entraîner le réseau.
Pour ce qui est du traitement automatique du langage, c'est la même chose, avant l'arrivée du deep learning, les chercheurs utilisaient couramment ce que l'on appelle les chaînes de Markov pour analyser les séries temporelles, et reconnaitre la parole.
Après l'arrivée du Deep Learning, ces derniers ont été remplacés par les réseaux neurones LSTM, qui sont nettement plus efficaces.
Pour l'extraction de caractéristiques, par exemple, avant l'arrivée de deep learning, l'analyse en composante principale était fréquemment utilisée pour extraire les caractéristiques des images.
Puis, de nos jours, ce sont les auto-encodeurs qui sont maintenant utilisés.
Ce que je veux dire par la c'est que en soi, toutes les tâches qu'on effectue aujourd'hui avec le deep learning, nous pouvions d'hors et déjà les effectuer avec le machine learning conventionnel.
C'est juste que c'était nettement plus compliqué pour l'ingénieur en machine learning à implémenter et que les performances étaient moins bonnes que ce que l'on peut observer couramment de nos jours avec le Deep Learning.
La seule vraie révolution majeure pour moi avec le Deep Learning que quasi aucun algorithme ne pouvait faire avant est
Et oui, si tu as suivi les informations récemment, tu as très probablement entendu parler des GANS, pour générative adversarial network.
Il s'agit de réseaux neuronaux qui permettent de créer de données inexistantes.
Cela peut être des visages de personnes inexistantes
ou encore des images de mangas, à tel point que bientôt je crois bien que l'on utilisera cette technique pour générer des bandes dessinées
ou encore transformer des phrases en images. Cette fonctionnalité-là sera plutôt à mon avis utilisée dans un futur lointain pour faire des adaptations filmographiques de nos romans préférés à moindre coût.
L'histoire du deep learning a principalement commencé en 1980 avec l'invention des réseaux de neurones convolutifs.
Comme je l'ai dit précédemment pour traiter une image auparavant, il était nécessaire qu'un ingénieur en machine learning se pose sur le projet, analyse et étudie les images, puis construise à la main le modèle.
Humainement, cela est possible si le nombre d'images et le type des images reste très limités, genre reconnaître 10 espèces de fleurs différentes.
Ou si encore les images sont simples telles que des caractères dactylographiés, lesquels sont aisément reconnaissables par un système OCR.
Mais le fait est qu’à cette époque, les systèmes de reconnaissance d'objet et particulièrement d'écriture manuscrite dont les banques avaient tant besoin pour reconnaître les chèques plafonnaient et n'arrivait pas à s'améliorer.
Ce fait n'est pas étonnant comme nous sommes 6 milliards d'humains sur la planète et que chacun à une écriture manuscrite différente.
YANN Lecun, ancien directeur du département de recherche en Intelligence artificielle de Facebook et prix Turing 2019 pour sa contribution au deep learning travaillais à cette époque sur la thématique de la reconnaissance automatique de chèque.
Long story, short, il a compris qu'humainement, construire un modèle mathématique à la main qui permettrait de reconnaître l'ensemble des écritures manuscrites serait impossible.
C'est pourquoi il s'est dit que plutôt que de le faire à la main, il allait automatiser l'opération.
L'idée un peu saut grenu qu'il a eu à donnée naissance à l'un des algorithmes de deep learning les plus utilisés à ce jour par les grosses firmes de Mountain View et de la Silicon Valley :
À la suite de cela, son système de reconnaissance de l'écriture manuscrite fonctionnant particulièrement bien a été pris et utilisé de très nombreuse banque.
Mais en plus de cela, il a été remarqué que cet algorithme fonctionnait très bien sur d'autre type de signaux tel que la voix humaine.
Il a donc été repris et utilisé dans de nombreux systèmes de reconnaissance.
Le Deep learning existait déjà depuis les années 1990, mais ce n'est que vers la fin des années 2010 qu'il a connu une croissance et une expansion fulgurante. Comme en témoigne la courbe ci-dessous qui montre le nombre d'articles de recherche dans le domaine biomédical qui ont utilisé le deep learning.
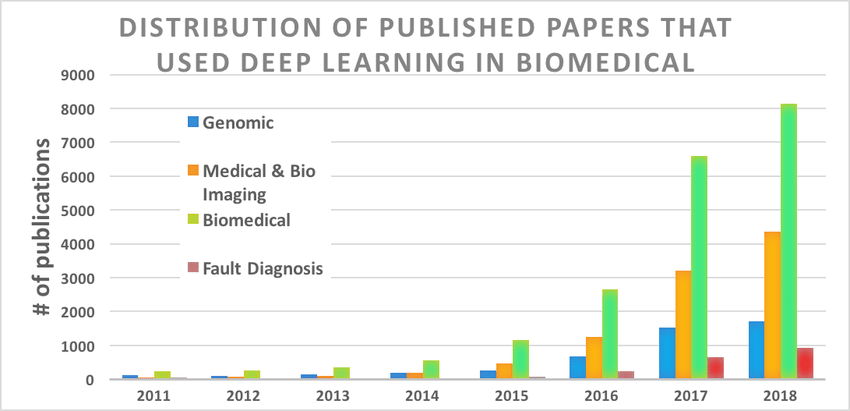
Source de l'image : Deep Learning in the Biomedical Applications: Recent and Future Status
Trois détonateurs principaux ont permis l'émergence du deep learning :
L'invention des réseaux de neurones convolutifs (YANN LECUNN : 1988)
L'invention des réseaux de neurones récurrents et plus particulièrement des réseaux de neurones Long Short Term Memory - LSTM - (Sepp Hochreiter et Jürgen Schmidhuber : 1997 )
La rapide augmentation de la puissance de calcul des ordinateurs
Les réseaux de neurones convolutif ont été inventés en 1988 par Yann LECUN un des trois pères fondateurs du deep learning à des fins de reconnaissance de chèques bancaires.
La particularité des réseaux de neurones convolutifs comparativement au technique de machine learning conventionnellement utilisé à l'époque (perceptron multicouche, JR48, Support Vector Machine etc....) est que ces réseaux sont capables de construire automatiquement à partir des données brutes un modèle mathématique capable d'extraire les informations contenu dans un signal (image, sont, vidéo, etc...) et de résoudre le problème de classification ou de régression posé.
Un peu plus haut dans cet article, je vous ai donné l'exemple de ce que ferait un ingénieur en machine learning pour construire une application de reconnaissance de fleur en vous disant qu'il prendrait plusieurs mesures différentes de la fleur et qu'il tenterait de classer ces dernières grâces à un classifieur. Dans le cas des réseaux de neurones convolutif, il n'est même pas nécessaire de prendre des mesures de la fleur, il suffit de mettre en entrée du réseau l'image de la fleur et le réseau de lui-même apprendra à la reconnaître.
À l'époque (en 1988), les réseaux de neurones convolutif ont été une invention à la fois révolutionnaire et un peut saut grenu, car il rentrait en opposition avec les schémas de l'époque qui voulait absolument que l'on dispose d'une ingénieur en machine learning pour extraire les caractéristiques.
Voici un schéma du réseau convolutionnel de neurones
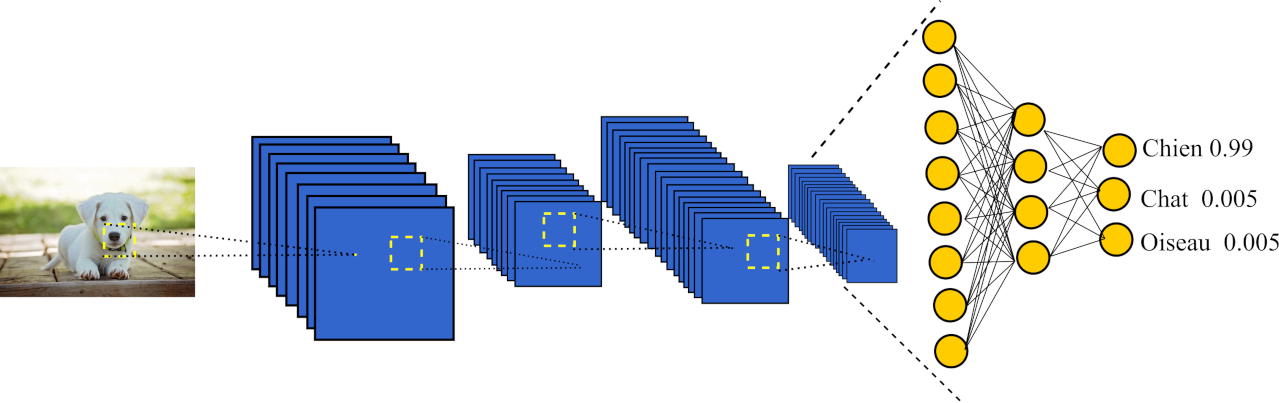
Ces réseaux sont principalement nés de la difficulté qu'avait la solution logicielle des laboratoires Bell à reconnaître l'écriture manuscrite sur les chèques bancaires. Yann LECUN, a alors fait face à une grosse difficulté : l'écriture manuscrite de chaque être humain est différente et peut être amenée à beaucoup varier d'un humain à l'autre. Construire manuellement un modèle pour chaque type d'écriture est un travail très chronophage et peu gratifiant, il a alors l'idée de laisser l'ordinateur construire automatiquement ce modèle et donne naissance aux réseaux de neurones convolutif.
Un fait intéressant des ces réseaux est que de manière générale, plus l'on rajoute de couches à ces réseaux (plus ils sont profonds) et plus les performances obtenues par ces derniers sont exceptionnelles. Cela est une première explication à l'invention du terme "deep learning".
Le système de reconnaissance proposé par Lecun est rapidement devenu l'un des plus utilisé à l'époque aux États-Unis tant est si bien qu'en 2000 il est utilisé pour la reconnaissance de plus de 10 % du nombre total de chèque généré aux États-Unis.
Un peu plus tard, mais toujours dans les années 2000 les CNN explosent tous les benchmarks obtenus par les meilleurs algorithmes de machine learning. Enfin en 2017, AlphaGo, une IA capable de jouer au jeu de go et utilisant des réseaux de neurones convolutifs, bat le champion du monde de go Ke Jie. Cet évènement marque un tournant sans précédent dans l’histoire de l’intelligence artificielle, car jusqu’alors aucune IA n’avait réussi à dépasser l’humain dans le jeu de go.
Les réseaux de neurones récurrents sont utilisés pour le traitement de série temporelle. Ils peuvent être utilisés pour diverses applications telles que la prédiction du cours des d'actions, la reconnaissance vocale, ou encore la reconnaissance d'actions dans des vidéos. Ce type de réseau se distingue d’autres types de réseaux neuronaux de par sa capacité à retenir les observations qui lui ont précédemment été soumises et à en déduire la réponse en fonction des informations extraites de ces observations. Il est l'équivalent donc de la mémoire de travail à court terme que nous avons.

Schéma d'un réseau de neurones récurrents
-Tensor-flow
-Keras
-PyTorch
-Theano
-CNTK
Le deep learning est un domaine de l’informatique lancée dans les années 2000 dont l’expansion continue à croitre jusqu’à présent. Il a constitué une étape supplémentaire dans l’évolution des machines, car maintenant les machines apprennent toutes seules à partir des données brutes comparativement à avant où elles avaient besoin d’un expert en machine learning afin d’analyser et d’interpréter les données. De ce fait, un simple programmeur initié à python est maintenant capable de créer une IA puissante.
Beaucoup d’algorithmes ont contribué au succès grandissant de cette ère, je citerais particulièrement les suivants: les réseaux convolutionnel de neurone, T-SNE, les auto-encodeurs, les machines de Boltzmann et les réseaux de neurones LSTM.
Les réseaux convolutionnel de neurones ont été inventés en 1988 par Yann Lecun (un des pères fondateurs du deep learning) qui travaillait à ce moment-là au laboratoire Bell. Initialement, ils avaient été inventés dans le but d’effectuer des tâches de reconnaissance de chèque. Le système a connu un tel succès qu'il fut utilisé pour la reconnaissance de 10 % du nombre total des chèques généré aux États-Unis dans les années 2000.
Il se fit discret par la suite, avant d’être utilisé quelques années plus tard pour d’autres tâches telles que la reconnaissance d’image , la reconnaissance vocale, la reconnaissance de situation (dans des jeux), ou encore la reconnaissance d’action et d’autres encore... Vient alors l’heure de la gloire pour Yann Lecun qui est officiellement reconnue comme l’un des plus grands de son temps. Aujourd’hui, les réseaux convolutionnel sont bien meilleurs que l’humain dans de nombreuses tâches telles que la reconnaissance visuelle.
Comment fonctionne ce système ?
Imaginez une image comme étant une grille de pixels, puis que sur cette image, vous appliquiez plusieurs matrices afin de la transformer. Vous obtiendriez alors plusieurs images différentes (une par matrice). Maintenant, redimensionnez les images obtenues en divisant leurs tailles par 2. Répétez ce processus jusqu’à obtenir de très très petites images d’à peine 2 ou 3 pixels. BRAVO! Vous venez de faire une passe d’un réseau convolutionnel de neurone. En bref, il s’agit de modifier l’image de plusieurs façons différentes puis de rétrécir les images résultantes et de répéter ce processus jusqu’à obtenir 3 ou 4 valeurs qui résumeront l’information contenue dans l’image.

Illustration de
La question qui se pose alors est comment l’image est-elle modifiée?
Des images vont être soumises au réseau de neurones avec leur catégorie afin de l’entraîner. Les modifications idéales à chacune des étapes seront trouvées grâce à un algorithme d’optimisation (descente du gradient), qui va successivement forcer le réseau à répondre par la catégorie de l’image qui lui a été soumise. Cela se fait en modifiant les valeurs des matrices appliquées aux images lors de la phase d’entraînement.
Le principe des auto-encodeurs est le suivant : un premier réseau de neurones appelé encodeur va prendre en entrée un vecteur de données de très grande dimension (> 1000) et va transformer ce vecteur en un vecteur de petite dimension (<20) . Par la suite, un second réseau de neurones appelé décodeur va prendre en entrée le vecteur de petite dimension et va reconstituer le vecteur de très grande dimension.
Il est important de préciser qu’entre le vecteur
d’entrée et le vecteur de sortie, il y aura une perte
d’information, mais celle-ci est généralement acceptable, car
très souvent il s’agit du bruit du vecteur d’entrée qui a été
retiré.

Pour ceux qui n’ont pas lu mon premier article sur la vision par ordinateur, je les invite à allez le lire afin de mieux comprendre la partie qui suit.
Prenons l’exemple d’un botaniste, qui au cours de sa formation a appris à reconnaitre différentes fleurs avec des critères telles que la longueur des pétales, la largeur des pétales, la couleur de la fleur, etc.
Supposons que ce botaniste a très souvent des clients qui lui demandent de différencier deux types de fleurs et que malheureusement il a énormément de mal avec les critères qu’il a appris à l’école à différencier ces deux espèces.
Il ne sait pas quoi faire jusqu’à ce qu’il entende parler par un de ses amis informaticiens des auto-encodeurs. Son ami lui dit “ écoute donne moi les images des fleurs que tu n’arrives pas à distinguer, je vais les passer dans l’auto-encodeur et ainsi extraire 10 mesures différentes qui te permettront de distinguer ces deux espèces de fleurs”.
Cela fait, le botaniste confit à son ami les images de ses fleurs. L’informaticien utilise l’encodeur afin d’encoder les images de fleur en mesures et s’assure qu’avec celle-ci en sortie du décodeur l’on retrouve bel et bien la fleur. Il remet à son ami les mesures. Parmi les 10 mesures que l’informaticien a extraites, le botaniste trouve celles qui permettent le mieux de distinguer les deux espèces de fleurs et règle ainsi son problème.
Une seconde utilisation des auto-encodeurs est la génération de données n’existant pas. En envoyant au décodeur un vecteur de caractéristique qui a été arbitrairement rédigé par un humain, il est possible de générer en sortie un vecteur de données n’existant pas à l’origine. Cela peut notamment s’appliquer à la création d’images artificielles, de vidéo artificiel, de voix ou encore de bandes dessinées.
Mais encore en envoyant au décodeur un vecteur de caractéristique extrait d’une image et modifié, il est possible de créer une variante de cette image. Cela permet notamment de créer des applications de modification de visage tel que celle utilisée dans les smartphones.
L’algorithme T-SNE a été développée par Geoffrey Hinton (un autre des pères fondateurs du Deep learning) et Laurens van der Maaten. Il permet de compresser des données en 2 ou 3 dimensions afin qu’elles soit visualisable dans un graphique deux ou trois dimensions.
Les machines de Boltzmann sont l’équivalent théorique des auto-encodeurs. Bien que je ne l’ai pas dit précédemment, il n’est pas prouvé théoriquement que les auto-encodeurs sont la meilleure manière de compresser des données, d’en extraire des caractéristiques, ou encore de générer des images.
Seulement en pratique, les auto-encodeurs s’avèrent être très efficaces et c’est la raison pour laquelle ces méthodes sont très utilisées. Théoriquement, les machines de Boltzmann sont éprouvées et leur efficacité a été démontrée par des preuves mathématiques.
Les réseaux de neurones récurrents sont des réseaux utilisés pour des taches de reconnaissance et de génération de séquence. Une séquence peut être un mot, une phrase, un texte, une action ( marquer un panier au basket), une musique, etc. La particularité de ces réseaux est le fait qu’il intègre une mémoire afin de se rappeler des informations qu’ils ont reçues en entrée auparavant.
Pour conclure, grâce au deep learning, il est possible aujourd’hui d’implémenter des tâches de reconnaissance d’objet sans être obligatoirement un expert dans le domaine de la vision par ordinateur.
Les librairies Tensorflow, Keras, Theano permettent de monter des réseaux de neurones et d’éditer leurs fonctions d’entrainement. De plus, d’autres taches telles que la création d’images, de vidéo deviennent accessibles sans aide humaine malgré le fait que les techniques employés pour celle-ci soient toujours en phase expérimentale.
La machine est donc en voit de rattraper et de dépasser l’humain. Les éléments qui actuellement l’en empêchant sont la capacité de calcul des machines qui est nettement inférieure à celle du cerveau humain et la faible compréhension que la communauté scientifique sur la manière dont le cerveau traite les informations.